Registers as a Solution to Vision Transformers’ Artifact Dilemma
Introduction
Transformers have revolutionized computer vision by enabling powerful visual representations. Vision Transformers (ViTs) excel in image classification, segmentation, and depth estimation tasks. However, ViTs suffers from a significant problem: high-norm tokens in feature maps, primarily in low-informative background areas, which introduce artifacts and hinder performance.
This issue is evident when comparing models trained with the DINO algorithm. While the original DINO model produces clean, interpretable attention maps, its successor, DINOv2, suffers from artifacts. This problem also affects popular models like OpenCLIP and DeiT-BASE, indicating a widespread challenge in the ViT architecture.
Researchers from FAIR, Meta, and INRIA propose a novel solution: introducing additional tokens, termed registers, into the input sequence of the Vision Transformer. These registers manage global information, effectively eliminating the artifacts. This solution enhances model performance, especially in object discovery tasks where DINOv2 with registers outperforms its counterpart without registers.
This article explores the problem of attention map artifacts, the proposed solution, and experimental results demonstrating its effectiveness. We also discuss broader implications for future transformer-based models and applications in computer vision.

Problem Formulation
Vision Transformers (ViTs) are prominent in computer vision for their ability to learn visual representations through attention mechanisms. However, they exhibit high-norm tokens, particularly in low-informative background areas. These artifacts disrupt feature maps and affect supervised and self-supervised ViTs like DINOv2, OpenCLIP, and DeiT-BASE.
Artifacts in Attention Maps:
High-norm tokens, approximately 10x larger in norm than other tokens appear primarily in the middle layers of the Vision Transformer during inference. They become prominent after extensive training on large models and are more about global image context than local information, repurposing redundant patch information for internal computations.

Quantitative and Qualitative Impact:
Though only 2% of the total tokens, high-norm tokens significantly impact model performance. DINOv2 models exhibit peaky outlier values in attention maps absent in the original DINO models, suggesting that DINO is an exception among ViTs. Qualitative analyses show these outlier tokens appear in redundant patches and perform poorly in positional embedding prediction and pixel reconstruction tasks.

Need for a Solution:
Addressing these artifacts is crucial as they lead to suboptimal performance in downstream tasks like object discovery and dense prediction. High-norm tokens degrade interpretability and effectiveness, necessitating a robust solution to enhance ViTs’ performance and reliability.
Artifacts in Local Features of DINOv2
High-norm tokens, or artifacts, are particularly pronounced in the DINOv2 model, disrupting the quality of local features. This section examines these artifacts’ nature, impact, and observations made during the investigation.
Identification of High-Norm Tokens:
Artifacts in DINOv2 are tokens with norms approximately ten times larger than the average token norm. These high-norm tokens constitute around 2% of the total tokens and appear in patches similar to their neighboring patches, indicating redundancy.
Emergence During Training:
These high-norm tokens appear around layer 15 of a 40-layer model and become noticeable only after substantial training. They are more prevalent in larger models, differentiating from regular tokens as training progresses.

Redundant Information and Poor Locality:
High-norm tokens appear in image patches with redundant information. Cosine similarity measurements show these outliers often reside in areas similar to neighboring patches. Evaluations using linear models for positional embedding prediction and pixel reconstruction indicate that high-norm tokens hold less local information.

Evaluation of Information Content:
High-norm tokens perform poorly in local information tasks but exhibit higher accuracy in image classification via linear probing, suggesting they aggregate global information beneficial for functions requiring a holistic image understanding.
Implications for Dense Prediction Tasks:
High-norm tokens lead to poorer performance in dense prediction tasks, disrupting the smoothness and interpretability of feature maps, which is crucial for tasks like object discovery and segmentation.
Hypothesis and Remediation
Hypothesis: Redundant Tokens and Global Information Storage:
Vision Transformers naturally recycle tokens from low-informative patches to store and process global information. High-norm tokens aggregate global information but disrupt tasks needing detailed local information.
Proposed Solution: Introduction of Register Tokens:
The researchers propose adding register tokens to the Vision Transformer input sequence. These learnable tokens manage global information, preventing high-norm tokens in patch embeddings and resulting in smoother feature maps.
Implementation of Register Tokens:
1. Adding Registers to the Input Sequence:
— Introduce additional register tokens to the sequence of image patches.
— Initialize these tokens with learnable parameters and position them after the patch embeddings.
— Adjust positional embeddings to accommodate the additional tokens.
2. Training with Registers:
— Train Vision Transformer models with the new input sequence, including register tokens.
— Monitor token norms to ensure the disappearance of high-norm artifacts.
3. Performance Evaluation:
— Evaluate models on tasks like image classification, segmentation, and object discovery.
— Compare the performance of models with and without register tokens.
Results and Benefits:
Adding register tokens eliminates high-norm artifacts in DINOv2 and other ViTs like OpenCLIP and DeiT-BASE. Models with registers exhibit smoother, more interpretable attention maps and improved performance in dense prediction tasks. DINOv2 with registers outperforms its counterpart without registers, approaching the original DINO model’s performance.
Experiments
Training Algorithms and Data:
The researchers validated register tokens using three Vision Transformer models: DeiT-III, OpenCLIP, and DINOv2, each representing different training paradigms — supervised, text-supervised, and self-supervised learning. These models were trained on large datasets like ImageNet-22k.

Evaluation of the Proposed Solution:
The goal was to assess the impact of register tokens on token norms and model performance. Adding register tokens effectively removes high-norm outliers, resulting in smoother feature maps and improved attention maps.
1. Effect on Token Norms:
— Models with register tokens showed no significant norm outliers.
— Quantitative measures and visual inspections confirmed the elimination of high-norm artifacts.
2. Improved Attention Maps:
— Register tokens resulted in cleaner, more interpretable attention maps free of artifacts.

Performance Metrics:
Models with register tokens were evaluated on several tasks, including image classification, segmentation, and depth estimation.
1. ImageNet Classification:
— Performance on ImageNet classification remained stable or improved with register tokens.
2. Segmentation and Depth Estimation:
— Linear probing on ADE20k segmentation and NYUd depth estimation showed performance improvements with registers.
3. Unsupervised Object Discovery:
— Significant improvements in unsupervised object discovery using LOST on VOC 2007, 2012, and COCO datasets.

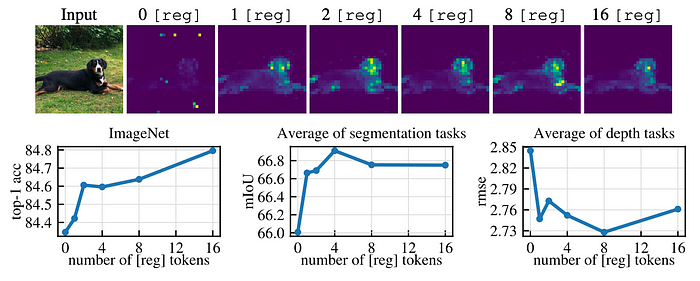
Optimal Number of Registers:
1. Optimal Number:
— One register token was sufficient to remove artifacts.
— More than one register improved performance further, with four registers providing the best balance.
2. Task-Specific Performance:
— Dense tasks like segmentation and depth estimation benefited most from a few registers.
— Image classification tasks showed marginal performance improvements with additional registers.
Qualitative Evaluation:
Visual inspections of attention maps and feature maps confirmed the benefits of register tokens.
1. Attention Maps:
— Visualizations showed cleaner attention maps with registers, focusing on semantically meaningful regions.
2. Feature Maps:
— Principal component analysis of feature maps showed fewer artifacts and more uniform distributions with registers.
Related Work
Feature Extraction with Pretrained Models:
Pretrained models have been foundational in computer vision. From AlexNet to ResNets, these models have evolved to extract robust visual features fine-tuned for specific tasks. Vision Transformers (ViTs) further enhanced this capability, effectively handling different modalities during training. Supervised methods like DeiT-III and text-supervised approaches like CLIP have yielded powerful visual foundation models.
Additional Tokens in Transformers:
Adding unique tokens to Transformer models is a well-established practice popularized by BERT. These tokens serve various purposes: classification, generative learning, and detection. The Memory Transformer introduced memory tokens, improving model performance in handling long sequences and complex tasks.
Registers in Vision Transformers:
The introduction of register tokens in Vision Transformers builds on this concept, providing dedicated tokens for global information processing. This approach mitigates artifacts and enhances the overall performance of the models, inspired by the Memory Transformer but adapted for vision tasks.
Conclusion
This work effectively addresses the artifacts in Vision Transformers by introducing register tokens. These tokens mitigate the high-norm artifacts that disrupt feature maps, resulting in smoother and more interpretable attention maps. The implementation of register tokens enhances model performance, particularly in dense prediction tasks such as object discovery and segmentation.
The addition of register tokens not only improves the robustness and accuracy of Vision Transformers like DINOv2, OpenCLIP, and DeiT-BASE but also maintains or enhances performance across various applications. This simple yet impactful modification demonstrates the potential for significant advancements in transformer-based models, ensuring they can be effectively applied to a wide range of computer vision tasks.
By isolating the task of managing global information to dedicated register tokens, the Vision Transformers can focus on preserving and processing detailed local information. This leads to a more balanced and effective approach to visual representation learning. This innovation paves the way for further research and improvements in transformer architectures, ultimately contributing to the advancement of computer vision technologies.
References
GitHub — kyegomez/Vit-RGTS: Open source implementation of “Vision Transformers Need Registers”
Vision Transformers Need Registers — Fixing a Bug in DINOv2? — YouTube
